Exercice Python : générateur de messages codés
Retour à la liste des articles
24 novembre 2019

Qui n'a jamais envoyé de messages codés ? Que ce soit sur les bancs d'école pour éviter de se faire coller par le ou la professeur-e ou, à l'époque de la Rome antique, pour éviter de se faire coller par Brutus, ce ne sont pas les occasions qui manquent. Dans cet exercice, tu vas créer ton propre système de chiffrement et de déchiffrement de messages. Regarde par toi-même :
>>> caesarize("C'est quoi le code du wifi?")
"F'hvw txrl oh frgh gx zlil?"
>>> uncaesarize("M'DL FHGH URPH")
"J'AI CEDE ROME"
On va utiliser un système de chiffrement appelé « chiffrement par décalage » ou encore « code de César ». Wikipédia décrit très bien ce système :
Le texte chiffré s'obtient en remplaçant chaque lettre du texte clair original par une lettre à distance fixe, toujours du même côté, dans l'ordre de l'alphabet. Pour les dernières lettres (dans le cas d'un décalage à droite), on reprend au début. Par exemple avec un décalage de 3 vers la droite, A est remplacé par D, B devient E, et ainsi jusqu'à W qui devient Z, puis X devient A etc.
En gros, ça donne quelque chose comme ça :
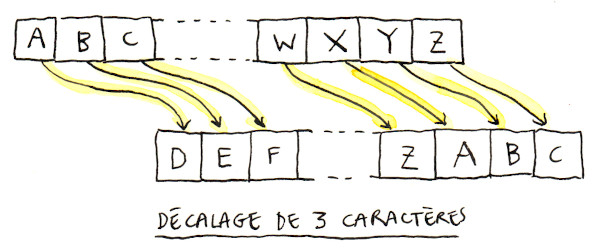
Je précise tout de même que ce système de chiffrement est facile à casser, et il ne devrait pas être utilisé pour partager des informations sensibles. Il n'en est pas moins amusant à utiliser, et encore plus à créer !
Prérequis pour cet article
Assure-toi d'avoir les connaissances nécessaires pour cet article en terminant la lecture du chapitre 6 « Un programme dynamique avec Python ».
Tu ne possèdes pas encore Génies du code ? Il s'agit d'une méthode illustrée, adaptée à tous les niveaux, qui te fera découvrir la programmation à travers la réalisation de ton propre site web de A à Z. Les deux premiers chapitres sont disponibles gratuitement dans leur intégralité !
Découvrir Génies du codeChiffrer quelques lettres
Comme première implémentation, pour s'échauffer, on va se limiter à 3 lettres, ce qui nous permettra de chiffrer le très important "COUCOU". On va utiliser un décalage de 3 lettres, ainsi :
- C devient F ;
- O devient R ;
- U devient X.
Exercice : chiffrer une lettre
Complète la fonction caesarize_letter ci-dessous pour qu'elle renvoie la
version chiffrée du paramètre letter, ou le contenu original du paramètre
letter si la lettre ne correspond pas à C, O ou U. Si tu bloques, aide-toi de
l'indice situé en dessous. Pour vérifier ton code, clique sur le bouton
Vérifier
sous l'éditeur. Une fois que ton code est valide, passe à la suite.
Le résultat des instructions print() s'affichera ici.
__check(caesarize_letter, 'F', args=['C']) __check(caesarize_letter, 'R', args=['O']) __check(caesarize_letter, 'X', args=['U']) __check(caesarize_letter, 'A', args=['A'])
Solution
def caesarize_letter(letter):
if letter == 'C':
return 'F'
elif letter == 'O':
return 'R'
elif letter == 'U':
return 'X'
else:
return letter
# L'instruction suivante devrait afficher FRXFRX
print(
caesarize_letter('C')
+ caesarize_letter('O')
+ caesarize_letter('U')
+ caesarize_letter('C')
+ caesarize_letter('O')
+ caesarize_letter('U')
)
Indice
Une approche possible consiste à utiliser une condition (avec l'instruction
if) pour que la fonction renvoie la bonne lettre suivant la
valeur du paramètre letter. Occupe-toi pour l'instant seulement
des lettres C, O et U en majuscules.
Exercice : chiffrer un texte
Maintenant que ton programme fonctionne, tu sais que COUCOU s'ecrit FRXFRX dans notre langage codé ! Avant d'ajouter la gestion du reste de l'alphabet, ajoutons une fonction pour chiffrer tout un texte, plutôt qu'un seul caractère. Ça rendra notre programme plus simple à utiliser.
Complète la fonction caesarize ci-dessous pour qu'elle utilise la fonction
caesarize_letter sur chaque lettre du texte puis renvoie le texte chiffré.
Le résultat des instructions print() s'affichera ici.
__check(caesarize, 'FRXFRX', args=['COUCOU']) __check(caesarize, 'FRX', args=['COU'])
Solution
def caesarize_letter(letter):
if letter == 'C':
return 'F'
elif letter == 'O':
return 'R'
elif letter == 'U':
return 'X'
else:
return letter
def caesarize(text):
encoded_letters = []
for letter in text:
encoded_letters.append(caesarize_letter(letter))
return ''.join(encoded_letters)
print(caesarize('COUCOU'))
Indice
Commence par créer une liste vide encoded_letters. Utilise
ensuite une boucle for pour parcourir les lettres du paramètre
text, et appeler la fonction caesarize_letter sur
chacune d'entre elles. Ajoute le résultat de cette fonction à la liste
encoded_letters grâce à
la méthode append. La méthode join te permettra ensuite
d'assembler cette liste pour renvoyer une chaîne de caractères. Par exemple
''.join(['C', 'O', 'U']) donne 'COU'.
Déchiffrement du texte chiffré
Exercice : déchiffrer une lettre et un texte
Ajoutons maintenant une fonction pour déchiffrer des lettres.
Complète la fonction uncaesarize_letter ci-dessous pour qu'elle fasse le
contraire de la fonction caesarize_letter. Comme pour caesarize_letter, tu
peux utiliser pour l'instant un bloc if.
Le résultat des instructions print() s'affichera ici.
__check(uncaesarize_letter, 'C', args=['F']) __check(uncaesarize_letter, 'O', args=['R']) __check(uncaesarize_letter, 'U', args=['X'])
Solution
def uncaesarize_letter(letter):
if letter == 'F':
return 'C'
elif letter == 'R':
return 'O'
elif letter == 'X':
return 'U'
else:
return letter
def caesarize_letter(letter):
if letter == 'C':
return 'F'
elif letter == 'O':
return 'R'
elif letter == 'U':
return 'X'
else:
return letter
def caesarize(text):
# Version simplifiée de la fonction `caesarize` grâce
# aux compréhensions de liste, je t'en reparlerai une autre fois
return ''.join([caesarize_letter(letter) for letter in text])
def uncaesarize(text):
return ''.join([uncaesarize_letter(letter) for letter in text])
print(uncaesarize('FRXFRX'))
Exercice : un dictionnaire à la place des conditions
On a maintenant un programme qui permet de chiffrer et déchiffrer 3 lettres. Il est
assez long, et tu te doutes probablement qu'il existe un moyen d'éviter que l'on
ait à écrire un bloc if avec 26 embranchements (et 26 autres embranchements
pour la fonction de déchiffrement !).
Une approche plus efficace consiste à utiliser un dictionnaire, que tu as vus au chapitre 6 et qui permettent d'associer des valeurs à des clés. Dans notre cas, on veut justement associer des valeurs (les lettres chiffrées) à des clés (les lettres d'origine). Ce n'est toujours pas la solution la plus efficace, mais c'est un bon exercice facultatif !
Complète les fonctions caesarize_letter et uncaesarize_letter ci-dessous
pour utiliser les dictionnaires caesarized_letters et uncaesarized_letters.
Il te suffit d'ajouter une seule ligne dans chaque fonction !
Le résultat des instructions print() s'affichera ici.
__check(uncaesarize_letter, 'C', args=['F']) __check(uncaesarize_letter, 'O', args=['R']) __check(uncaesarize_letter, 'U', args=['X']) __check(caesarize_letter, 'F', args=['C']) __check(caesarize_letter, 'R', args=['O']) __check(caesarize_letter, 'X', args=['U']) __check(caesarize_letter, 'A', args=['A'])
Solution
caesarized_letters = {'C': 'F', 'O': 'R', 'U': 'X'}
uncaesarized_letters = {
caesar_letter: letter
for letter, caesar_letter in caesarized_letters.items()
}
def caesarize_letter(letter):
return caesarized_letters.get(letter, letter)
def uncaesarize_letter(letter):
return uncaesarized_letters.get(letter, letter)
def caesarize(text):
return ''.join([caesarize_letter(letter) for letter in text])
def uncaesarize(text):
return ''.join([uncaesarize_letter(letter) for letter in text])
print(caesarize('COUCOU'))
print(uncaesarize('FRXFRX'))
Le code est déjà plus court et plus lisible grâce à l'utilisation de
dictionnaires. Lorsque tu te retrouves à écrire des blocs if à rallonge,
pense à utiliser un dictionnaire à la place ! Intéressons-nous maintenant au
reste de l'alphabet pour avoir une fonction qui permet de chiffrer toutes les
lettres. Plutôt que de faire le travail manuellement en ajoutant toutes les
lettres de l'alphabet dans le dictionnaire ci-dessus, laissons
l'ordinateur faire ce calcul.
Chiffrer et déchiffrer tout l'alphabet
Pour comprendre comment calculer automatiquement ces décalages, il est probablement nécessaire que je te rafraîchisse la mémoire en ce qui concerne l'encodage, dont je t'ai déjà parlé au chapitre 2. L'encodage définit la façon dont les caractères sont traduits sous forme de nombres. En Python, cette traduction se fait en suivant le standard Unicode, qui définit la correspondance numérique pour chaque lettre. Tu peux regarder la correspondance entre les lettres et leur représentation numérique par exemple sur la page Wikipédia sur l'Unicode.
Heureusement, tu n'as pas besoin d'apprendre cette table par cœur. La fonction Python
ord permet de connaître le code Unicode
d'une lettre donnée. Exécute le programme suivant pour voir le code Unicode des
trois premières et dernières lettres de l'alphabet.
Le résultat des instructions print() s'affichera ici.
Tu vois que les lettres majuscules sont représentées par une suite allant de 65 (A) à 90 (Z), alors que les lettres minuscules sont représentées par une suite allant de 97 (a) à 122 (z). Utilisons cette information pour simplifier la fonction pour chiffrer une lettre, et par la même occasion lui faire gérer toutes les lettres de l'alphabet !
Exercice : ajouter les lettres manquantes
Complète les fonctions caesarize_letter et uncaesarize_letter ci-dessous
pour gérer toutes les lettres de l'alphabet. Fais attention de
ne chiffrer que les lettres de l'alphabet entre a et z ou entre A
et Z.
Le résultat des instructions print() s'affichera ici.
__check(caesarize, 'FRXFRX MXOLH', args=['COUCOU JULIE'])
__check(uncaesarize, 'COUCOU JULIE', args=['FRXFRX MXOLH'])
__check(uncaesarize, 'COUCOU JULIE', args=[caesarize('COUCOU JULIE')])
Solution
def uncaesarize_letter(letter):
if 'A' <= letter.upper() <= 'Z':
return chr(ord(letter) - 3)
else:
return letter
def caesarize_letter(letter):
if 'A' <= letter.upper() <= 'Z':
return chr(ord(letter) + 3)
else:
return letter
def caesarize(text):
return ''.join([caesarize_letter(letter) for letter in text])
def uncaesarize(text):
return ''.join([uncaesarize_letter(letter) for letter in text])
print(caesarize('COUCOU JULIE'))
Indice
Utilise la fonction ord pour calculer le code Unicode de la lettre chiffrée,
et la fonction chr pour convertir un code Unicode en caractère.
Et voilà, tu peux maintenant (presque) chiffrer et déchiffrer toutes les lettres
de l'alphabet ! Pourquoi « presque » ? Essaie d'ajouter l'instruction
print(caesarize('XYZ')) à ton programme et regarde ce qui s'affiche... d'après
notre schéma, le résultat devrait être « ABC », mais à la place on obtient
« [\] ». Gloups ! Est-ce que tu devines pourquoi ? Je te donne un indice :
observe le résultat de l'instruction print(ord('[')). Eh oui, le code du
caractère « [ » est 91. C'est donc la lettre qui suit le Z majuscule dans
Unicode !
Exercice : gérer le retour à la première lettre
Pour résoudre ce problème, on va devoir faire un peu de maths (désolé !) Regardons de nouveau le schéma de correspondance entre les lettres et leur version chiffrée, et ajoutons-y le code Unicode de chaque lettre (en jaune) pour y voir plus clair :
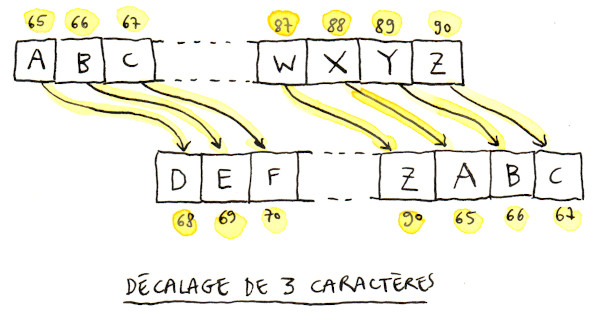
Entre 65 et 87, il suffit d'additioner 3 pour avoir la correspondance, mais une
fois que l'on a atteint le code 88, on doit recommencer à 65 (plutôt que 91). Ce
genre de calculs « cycliques » se résolvent généralement à l'aide de l'opérateur
% (modulo), qui renvoie le reste d'une division entière. Par exemple 29 % 26
donne 3, parce que 29 divisé par 26 donne 1 fois 26, avec un reste de 3.
Complète les fonctions caesarize_letter et uncaesarize_letter ci-dessous
pour gérer le retour à la première lettre en cas de dépassement. Cet exercice
peut être assez difficile, n'hésite pas à consulter les indices ci-dessous pour t'aider.
Le résultat des instructions print() s'affichera ici.
__check(caesarize, 'Txhov ehdxa aborskrqhv!', args=['Quels beaux xylophones!']) __check(uncaesarize, 'Quels beaux xylophones!', args=['Txhov ehdxa aborskrqhv!'])
Solution
def caesarize_letter(letter):
if 'A' <= letter.upper() <= 'Z':
start = ord('a') if letter.islower() else ord('A')
return chr((ord(letter) - start + 3) % 26 + start)
else:
return letter
def uncaesarize_letter(letter):
if 'A' <= letter.upper() <= 'Z':
start = ord('a') if letter.islower() else ord('A')
return chr((ord(letter) - start - 3) % 26 + start)
else:
return letter
def caesarize(text):
return ''.join([caesarize_letter(letter) for letter in text])
def uncaesarize(text):
return ''.join([uncaesarize_letter(letter) for letter in text])
print(caesarize('Quels beaux xylophones!'))
Indice
Prenons par exemple la lettre X, code Unicode 88. C'est un exemple intéressant parce qu'elle crée un retour au début de l'alphabet.
- Soustrais 65 pour avoir sa position dans l'alphabet (0 = A, 1 = B, 2 = C, etc) : 88 - 65 = 23 ;
- Ajoute le décalage pour avoir la version chiffrée de la lettre : 23 + 3 = 26 ;
- Applique un modulo 26 pour gérer le retour au début de l'alphabet si nécessaire : 26 % 26 = 0 ;
- Ajoute 65 pour avoir le code Unicode correspondant : 0 + 65 = 65.
- Utilise la fonction
chrpour transformer ce code en caractère.
Procède de la même façon pour les lettres minuscules, en utilisant le code Unicode de la première lettre minuscule (a), autrement dit 97, au lieu de 65.
Exercice : gérer n'importe quel décalage
Pour plus de sécurité, tu voudras peut-être changer régulièrement le décalage, et
ne pas toujours utiliser un décalage de 3. On peut ajouter un paramètre à la
fonction caesarize_letter pour lui indiquer le décalage à appliquer.
L'ajout de ce paramètre va même simplifier ton code en te permettant de
supprimer la fonction uncaesarize_letter. Il suffit en effet d'appeler
caesarize_letter avec un décalage négatif pour aller dans l'autre sens !
Ajoute un paramètre shift, qui représente le décalage à appliquer, à la
fonction caesarize_letter ci-dessous,
Le résultat des instructions print() s'affichera ici.
__check(caesarize, 'Aeovc lokeh hivyzryxoc!', args=['Quels beaux xylophones!', 10]) __check(uncaesarize, 'Quels beaux xylophones!', args=['Aeovc lokeh hivyzryxoc!', 10])
Solution
def caesarize_letter(letter, shift):
if 'A' <= letter.upper() <= 'Z':
start = ord('a') if letter.islower() else ord('A')
return chr((ord(letter) - start + shift) % 26 + start)
else:
return letter
def caesarize(text, shift):
return ''.join([caesarize_letter(letter, shift) for letter in text])
def uncaesarize(text, shift):
return ''.join([caesarize_letter(letter, -1 * shift) for letter in text])
print(caesarize('Quels beaux xylophones!', 10))
Et voilà le travail, tu as maintenant ton propre système pour chiffrer et déchiffrer des messages !
On est parti-e-s d'une approche intuitive (avec des conditions ou un dictionnaire) qui a eu l'avantage de t'aider à comprendre le fonctionnement de ce système de chiffrement, pour finalement arriver à une solution entièrement automatisée.
Tu peux encore ajouter de l'interactivité à ton programme en utilisant la
fonction input pour demander à
l'utilisateur-trice d'entrer le texte à chiffrer ou à déchiffrer, ainsi
qu'éventuellement le décalage à utiliser. Tu pourrais aussi gérer les lettres
accentuées, en les remplaçant par leur équivalent non accentué.
À toi de jouer !
Tu veux en savoir plus ?
Génies du code est une méthode illustrée, adaptée à tous les niveaux, qui t'initiera à la programmation à travers la réalisation de ton propre site web de A à Z. Les deux premiers chapitres sont disponibles gratuitement dans leur intégralité !
Et aussi, fais un tour sur les autres articles, tous plus intéressants les uns que les autres, en toute modestie.